

자주 쓰는 함수
split() - 데이터를 분리하는데 사용한다.
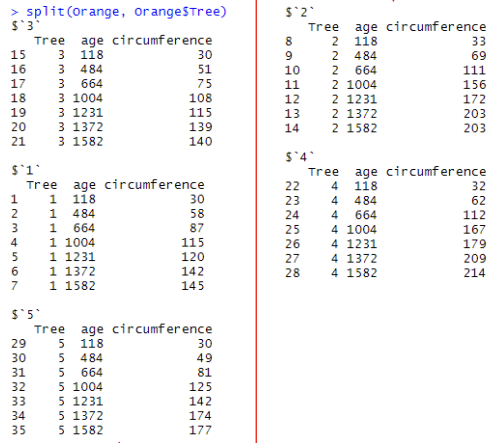
lapply(split(Orange$circumference, Orange$Tree), mean)
$`3`
[1] 94
$`1`
[1] 99.57143
$`5`
[1] 111.1429
$`2`
[1] 135.2857
$`4`
[1] 139.2857lapply()를 적용해서 Orange의 Tree별 circumference의 평균을 구할 수 있다.
subset() : 전체 중 특정 조건을 만족하는 부분만 원할 때 사용한다.
> subset(Orange, Tree==1)
Tree age circumference
1 1 118 30
2 1 484 58
3 1 664 87
4 1 1004 115
5 1 1231 120
6 1 1372 142
7 1 1582 145> subset(Orange, select=-c(Tree))
age circumference
1 118 30
2 484 58
3 664 87
4 1004 115
5 1231 120
6 1372 142
7 1582 145select 인자를 지정하면 특정 열을 선택하거나 제외 가능하다.
특정 열을 제외하고자한다면 '-'를 열이름 앞에 붙이면 된다.
벡터 연산
> subset(Orange, Tree==1 & age >3)
Tree age circumference
1 1 118 30
2 1 484 58
3 1 664 87
4 1 1004 115
5 1 1231 120
6 1 1372 142
7 1 1582 145벡터간 연산에서의 AND는 &&가 아니라 &를 사용한다.
with () : 함수를 사용하여. 원하는 값을 간단히 적을 수 있다.
> with(Orange,{
+ print(mean(age))
+ print(mean(circumference))})
[1] 922.1429
[1] 115.8571stack() : 데이터를 그룹별로 쌓는다.
> a<-data.frame(x=c(1, 4, 7),
+ y=c(2, 9, 6),
+ z=c(4, 3, 1))
> (stackedA<-stack(a))
values ind
1 1 x
2 4 x
3 7 x
4 2 y
5 9 y
6 6 y
7 4 z
8 3 z
9 1 z
>unstack() : 스택 함수를 통해 반환된 데이터를 원래 상태로 되돌리는데 사용한다.
> unstack(stackedA,values~ind)
x y z
1 1 2 4
2 4 9 3
3 7 6 1SQL 구문 사용
데이터 처리 함수들 없이 SQL문을 이용하여 데이터를 편리하게 조작할 수 있다.
install.packages("sqldf")
library(sqldf)Orange 데이터 중 Tree가 1인 age의 평균 구하기
sqldf("select avg([age]) from Orange where Tree = 1")
avg([age])
1 922.14291이면 행 방향, 2이면 열 방향이다.
plyr 패키지 사용
plyr은 데이터를 분할하고 분할된 데이터에 특정 함수를 적용하고 그 결과를 재조합해 주는 패키지이다.
adply() : 배열(a)을 받아 데이터프레임(d)으로 반환하는 함수이다.
> adply(iris,
+ 1,
+ function(row) {
+ data.frame(
+ sepal_ge_5_setosa=c(row$Sepal.Length >= 5.0 &
+ row$Species == "setosa"))})
Sepal.Length Sepal.Width Petal.Length Petal.Width Species sepal_ge_5_setosa
1 5.1 3.5 1.4 0.2 setosa TRUE
2 4.9 3.0 1.4 0.2 setosa FALSE
3 4.7 3.2 1.3 0.2 setosa FALSE
4 4.6 3.1 1.5 0.2 setosa FALSE
5 5.0 3.6 1.4 0.2 setosa TRUE
6 5.4 3.9 1.7 0.4 setosa TRUEddply(): 데이터프레임을 입력받아 를 받아 데이터프레임을 내보낼 때 사용한다.
ddply(iris, .(species), function(x) {data.frame(SWmean = mean(x$Petal.Length))})
Species SWmean
1 setos 1.462
2 versicolor 4.260
3 virginica 5.552출력시 칼럼명은 SWmean으로 지정하였다.
데이터를 그룹짓는 변수는 .()안에 기록한다.
setkey() : 함수를 사용해 색인을 만들어 두었다가 검색 시 사용한다.
> DF <- data.frame(x = runif(13000000), y=rep(LETTERS, each = 50000))
> str(DF)
'data.frame': 13000000 obs. of 2 variables:
$ x: num 0.2329 0.4013 0.5484 0.5703 0.0414 ...
$ y: chr "A" "A" "A" "A" ...
> system.time(x <- DF[DF$y=="D", ])
사용자 시스템 elapsed
0.21 0.00 0.21
> DT <- as.data.table(DF)
> setkey(DT, y)
> system.time( x<- DT[J("D"), ])
사용자 시스템 elapsed
0 0 0찾고자 하는 데이터를 setkey함수 안에 설정해준다.
인덱스는 데이터 분포를 생각하여 설정하여 준다.
'플레이데이터 빅데이터 부트캠프 12기 > R' 카테고리의 다른 글
| [플레이데이터 빅데이터 부트캠프]R 프로그래밍 - 응용 (0) | 2022.09.19 |
|---|---|
| [플레이데이터 빅데이터 부트캠프]R 프로그래밍 - 그래프 (0) | 2022.09.14 |
| [플레이데이터 빅데이터 부트캠프]R 프로그래밍 - 데이터 조작(1) (0) | 2022.09.14 |
| [플레이데이터 빅데이터 부트캠프]R 프로그래밍 - 조건문 반복문 함수 (0) | 2022.09.13 |
| [플레이데이터 빅데이터 부트캠프]R 프로그래밍 - 변수, 자료형 (1) | 2022.09.13 |