

kowiki를 사용한 텍스트 분석
Corpus란? 자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합이다.
(모두의 말 뭉치를 참고해 보자.)
파일 확인



kowiki 말뭉치에는 '지미 카터', '수학', '수학 상수', '문학' 등 여러 주제별로 설명글이 들어가 있다.
Word Tokenizer
문장을 단어별로 나누기
우선 정규표현식 사용법을 익혀 보자.
- re.sub (정규 표현식, 치환 문자, 대상 문자열)
- 정규 표현식 - 검색 패턴을 지정
- 치환 문자 - 변경하고 싶은 문자
- 대상 문자열 - 검색 대상이 되는 문자열
예시)

첫 번째 예시는 문장을 . , ! ? 등을 기준으로 한칸씩 띄어주며 바꿔주고, 아래칸은 . , ! ? 등을 띄어쓰기로 완전히 바꿔준다.
우리는 Word Tokenizer를 사용할 때 첫 번째 정규 표현식 예시를 사용하기로 한다.
실습
한국어 위키의 전체 단어수를 세어보자.

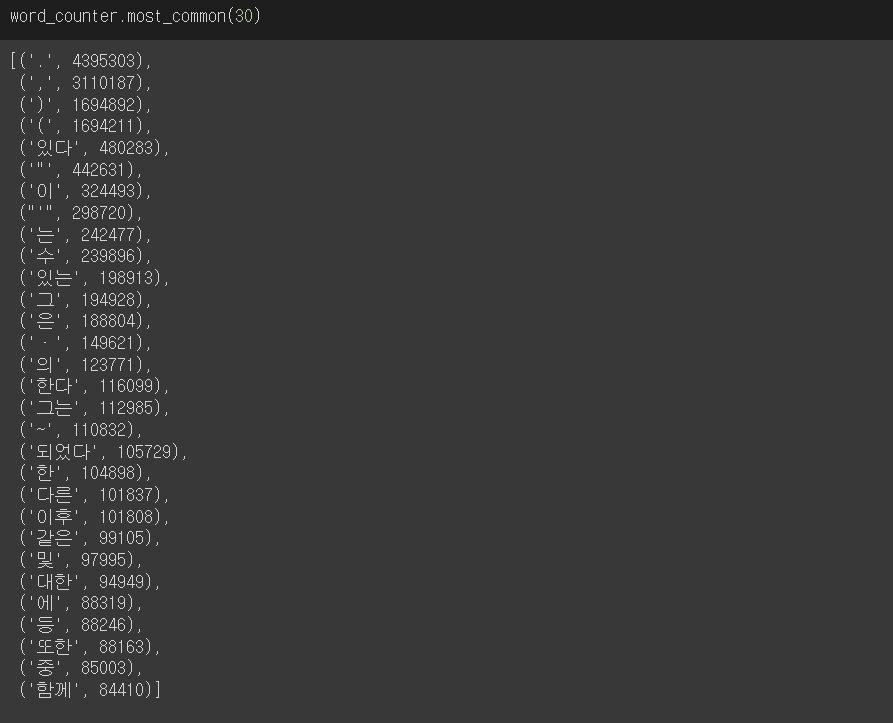
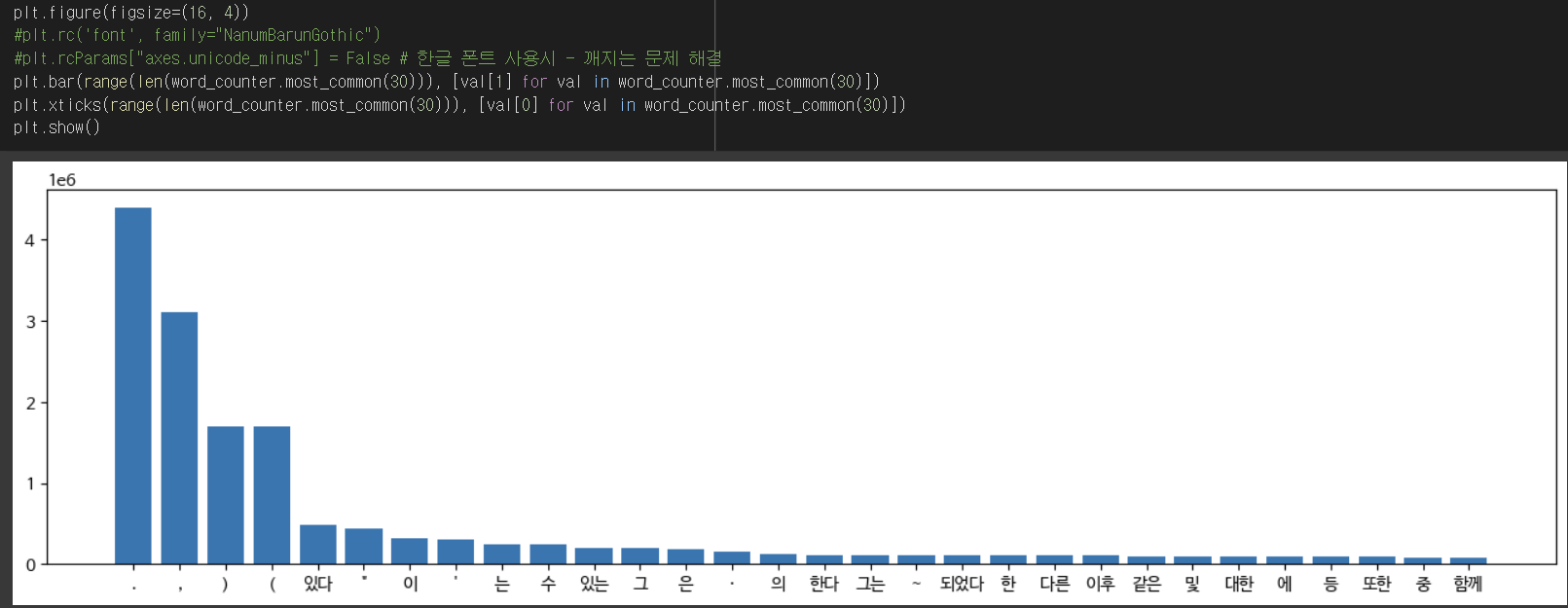
kowiki에서 가장 많은 수 30개를 'BarChart'로 시각화 해보자.
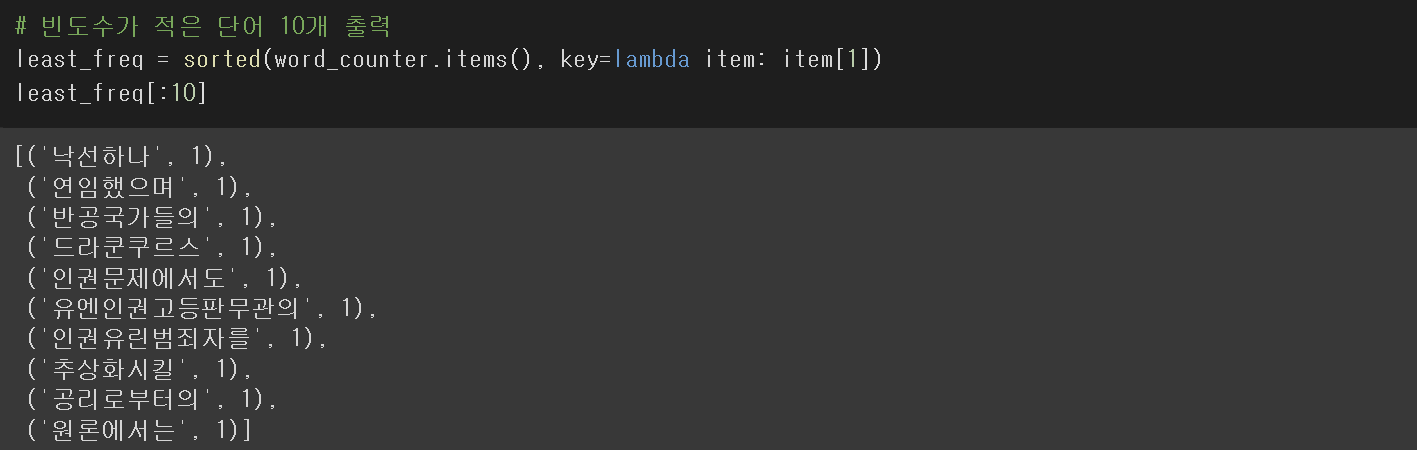
kowiki에서 가장 적은 수 10개를 뽑아보자.
Word ID Vocab
단어들을 딕셔너리 형태로 만들어 놓으면, 필요할 때 찾아서 연산을 해줄 수 있다.
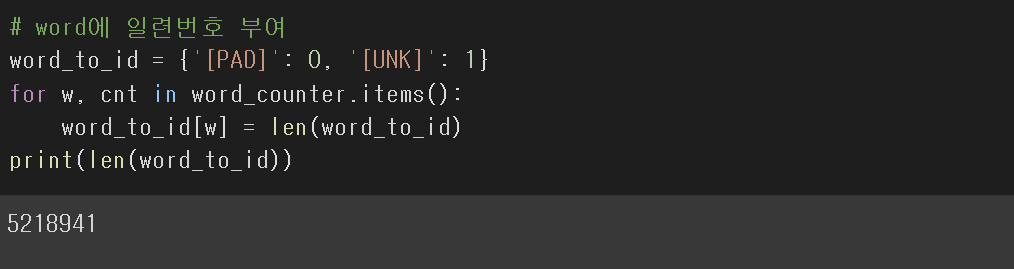
word_to_id라는 딕셔너리가 단어가 추가될 때마다, 딕셔너리의 길이가 늘어나는 만큼 단어들이 id 값을 부여받게끔 설계하였다.

Morp Tokenizer
Konlpy 형태소 분석기(Okt, Mecab)를 사용한다.

Morph Tokenizer : 형태소 단위로 분할한다.
형태소란? : 뜻을 가진 가장 작은 말의 단위를 말한다.
예시)
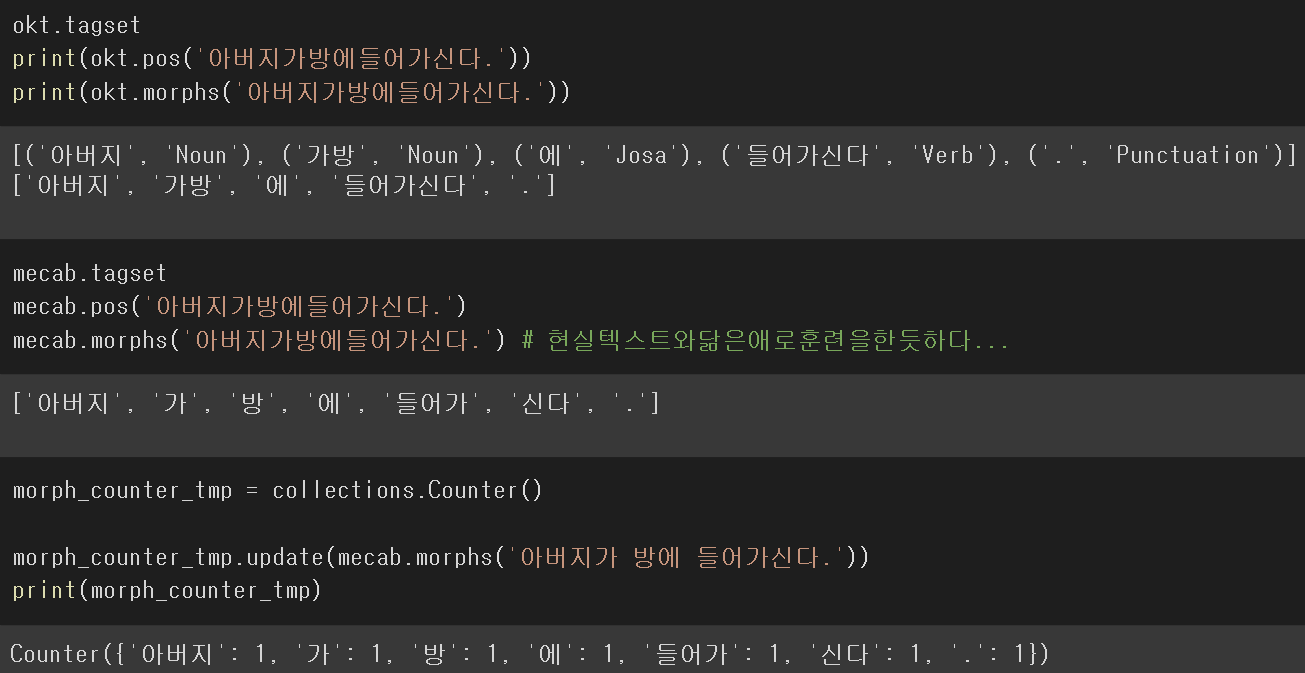
실습
한국어 위키의 전체 형태소 단위 단어수를 세어보자.
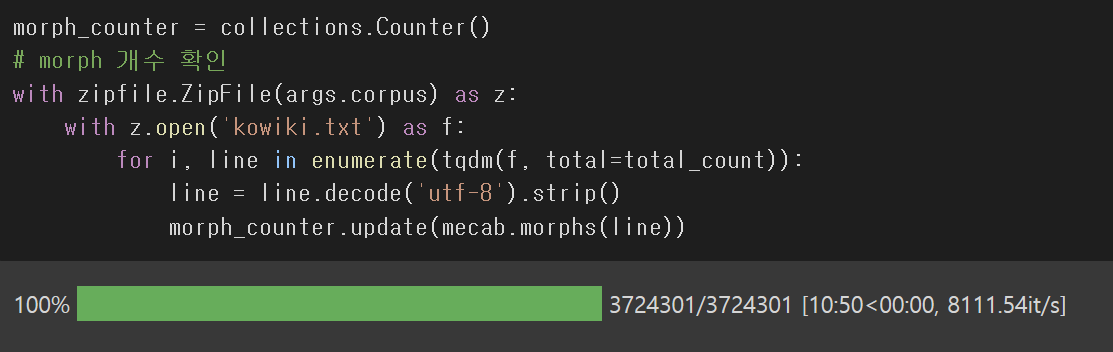

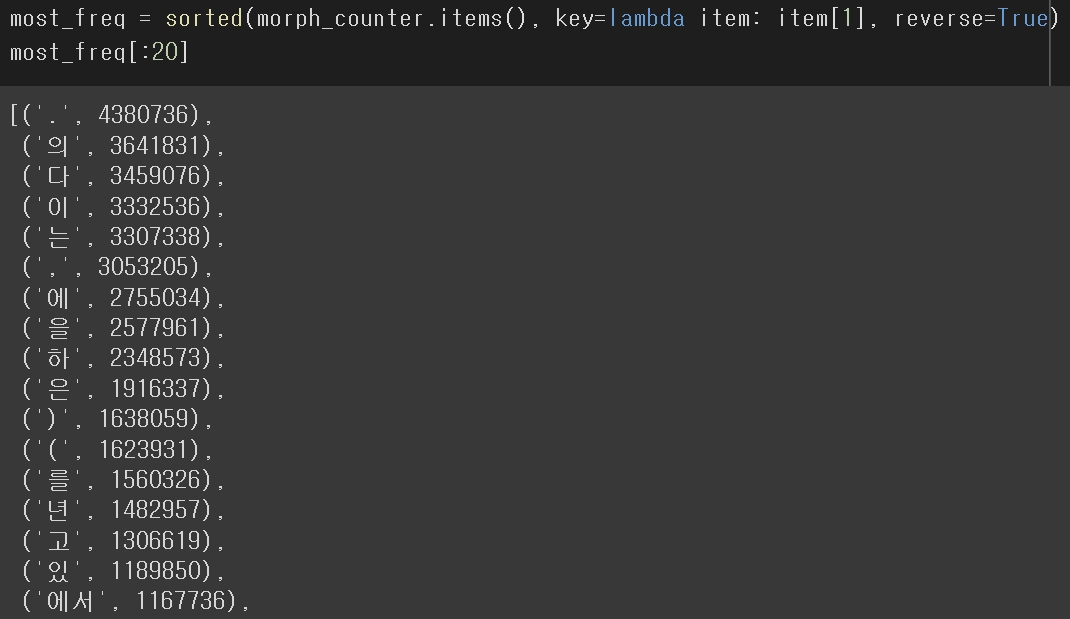
- 텍스트 분석을 할 때, 어느 단어로 텍스트를 끊을지 부터 생각해봐야한다.
- Okt보다 Mecab이 한국어 특성에 맞게끔 좀 더 잘 인식된다고 한다.
- 품사 단위로 끊는게 가장 효과가 좋은 연구 결과가 있다.
Sentencepiece
SentencePiece는 Google에서 2018년도에 공개한 오픈소스 라이브러리이다.
문장을 끊어주는 Tokenizer로 사용할 수 있다.
Sentencepiece 함수 사용법
- encode_as_pieces : 문자열을 token으로 분할하는 함수
- decode_pieces : token을 문자열로 복원하는 함수
- encode_as_ids : 문자열을 숫자로 분할하는 함수
- decode_ids : 숫자를 문자열로 복원하는 함수
- piece_to_id : token을 숫자로 변경하는 함수
- id_to_piece : 숫자를 token으로 변경하는 함수
Sentencepiece를 활용한 한국어 토크나이저 만들기
Mecab 형태소 분리기를 사용하여 형태소 단위로 쪼갠 후 Sentencepiece에 넣어주면 성능이 향상된다.
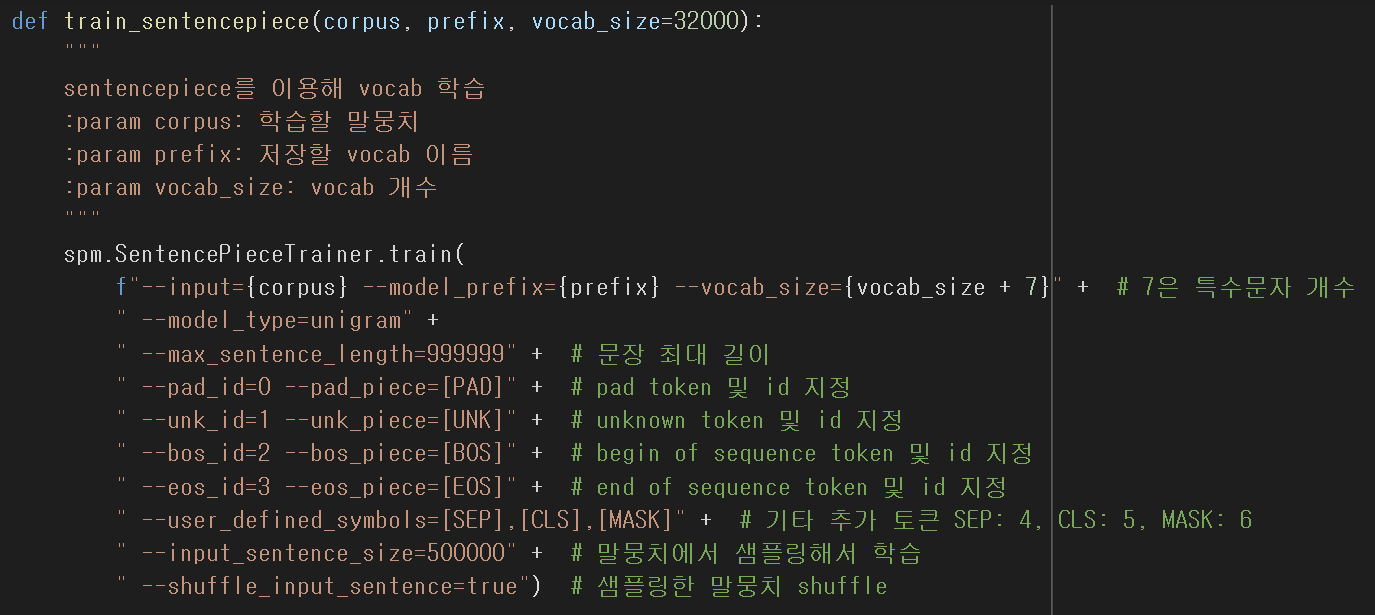
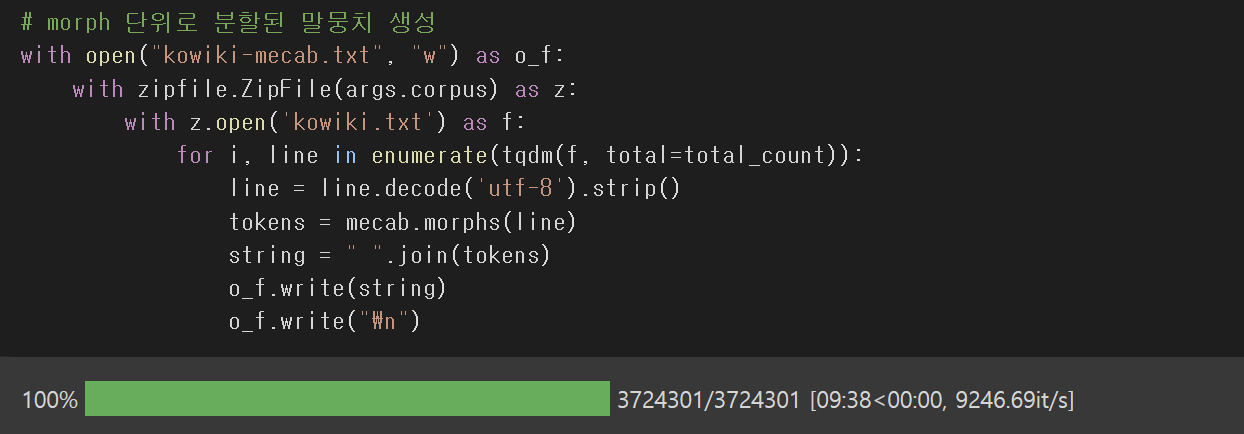
kowiki 텍스트 파일을 Mecab으로 형태소 단위로 분리된 후 "Kowiki-mecab"이라는 텍스트 파일로 새로 만들고 있다.


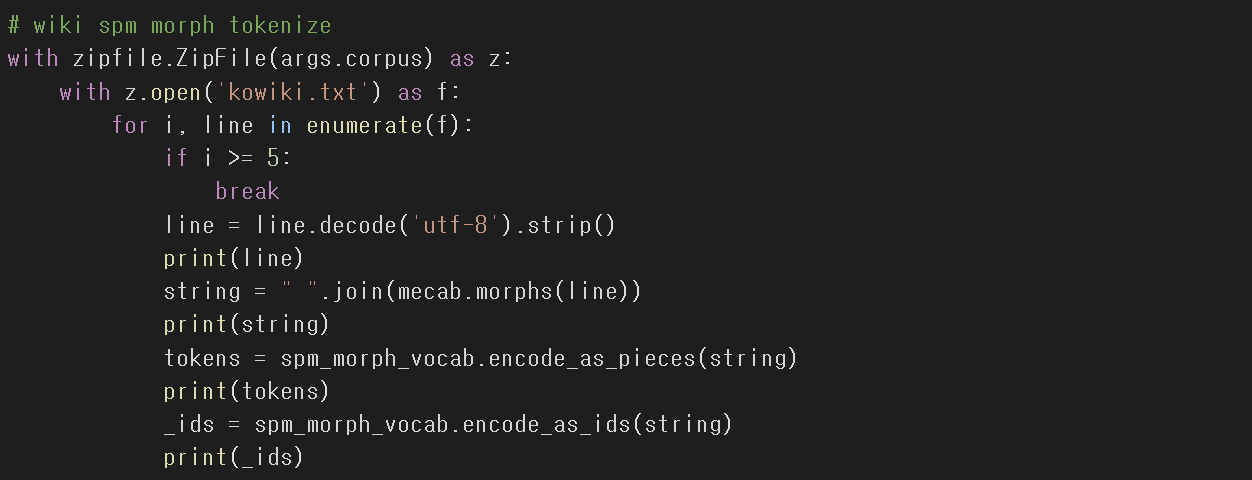
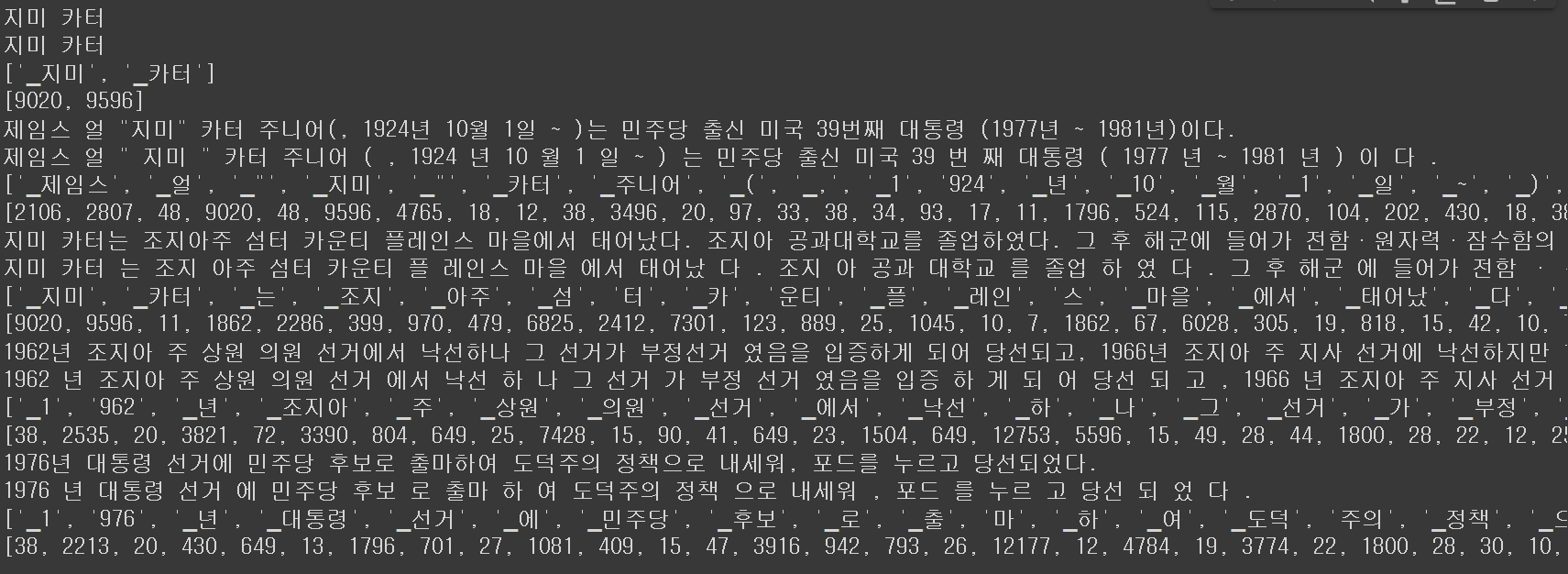
Sentencepiece 라이브러리를 사용하여 Kowiki 문장을 일정 기준으로 끊어준 것을 확인할 수 있다.
가장 아래 출력한 값은 단어의 ID 값들이다.
'플레이데이터 빅데이터 부트캠프 12기 > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 머신러닝 성능 평가 지표 정리 (0) | 2022.11.24 |
|---|---|
| [플레이데이터 빅데이터 부트캠프]딥러닝 미니 프로젝트 (0) | 2022.08.13 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 RNN, LSTM (0) | 2022.08.11 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 Teachable Machine (0) | 2022.08.10 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 전이 학습 (0) | 2022.08.10 |