

RNN(Recurrent Neural Network, 순환신경망)
- 순서가 있는 데이터를 처리하기 위한 Neural Network이다.
- 순서가 있는 데이터는 음성, 언어, 주가 등 발생 순서가 중요한 데이터를 의미한다.
- 문장에서 이전에 발생한 단어를 보고 다음 단어를 예측하는 경우이다.
Feed Forward Network
- 일반적인 구조의 신경망
- 입력->은닉->출력층으로 이어지는 단방향 구조이다.
Recurrent Network
- 이전 층, 또는 스텝의 출력이 다시 입력으로 연결되는 신경망 구조이다.
- 각 스텝마다 이전 상태를 기억하는 시스템이다.
- 시계열(날씨, 주가 등), 자연어와 같이 시간의 흐름에 따라 변화하는 데이터에 적합하다.
- 동일한 변수를 back propagation through time 하여 조금씩 조절하는 구조이다.
- 시간이 거리가 멀어질수록, 이전의 입력 값이 희석된다.

활성화 함수
- 활성화 함수로 tanh를 쓴다.(비 선형성을 뚜렷하게 한다.)
- 만약 CNN과 같이 Relu를 함수를 사용하면, 이전 값이 커짐에 따라 전체적인 출력이 발산하는 문제가 생길 수 있다.
- 과거의 값들을 재귀적으로 사용할 때, 이를 normailzing 하는 것이 필요하며 기울기의 역전파가 더 잘 되는 tanh를 사용한다.
RNN 모델 구현
시퀸스 예측 모델 만들기
다음 순서를 예측하는 모델 : [0.0, 0.1, 0.2, 0.3]이라는 연속된 숫자가 주어지는 경우 [0.4]를 예측하는 네트워크를 만들어보자.
데이터 생성
모델 생성

return_sequence 파라미터 : layer를 회귀할 때 사용한다.
input shape=[4, 1] : [timesteps(4번 반복), input_dim(입력 벡터의 크기)]
단순한 문제인 경우 층을 너무 깊게 쌓으면 정확도가 낮게 나올 수도 있다. ->하나의 층을 사용한다.
모델 평가
LSTM
- 히든 스테이트에 cell-state를 추가하여, 예전 정보가 희석되는 것을 막아준다.
- 아주 오래된 기억이나, 불필요한 정보를 걸러서 옆의 셀에 전달해 준다.
- Forget gate는 문자의 중요도를 파악하여, 다음 셀로 내보낼지 안 내보낼지 파악하는 역할을 한다.
- 텍스트 분석에 많이 사용한다.
- activation 함수는 'tanh'를 사용한다.
LSTM을 사용한 감성분석
데이터 불러오기
데이터의 뒷부분에서 라벨값을 train_Y, test_Y 값으로 사용한다.
데이터 전처리
GitHub - yoonkim/CNN_sentence: CNNs for sentence classification
CNNs for sentence classification. Contribute to yoonkim/CNN_sentence development by creating an account on GitHub.
github.com
한글 전처리에서 많이 사용하는 코드를 인용하였다.
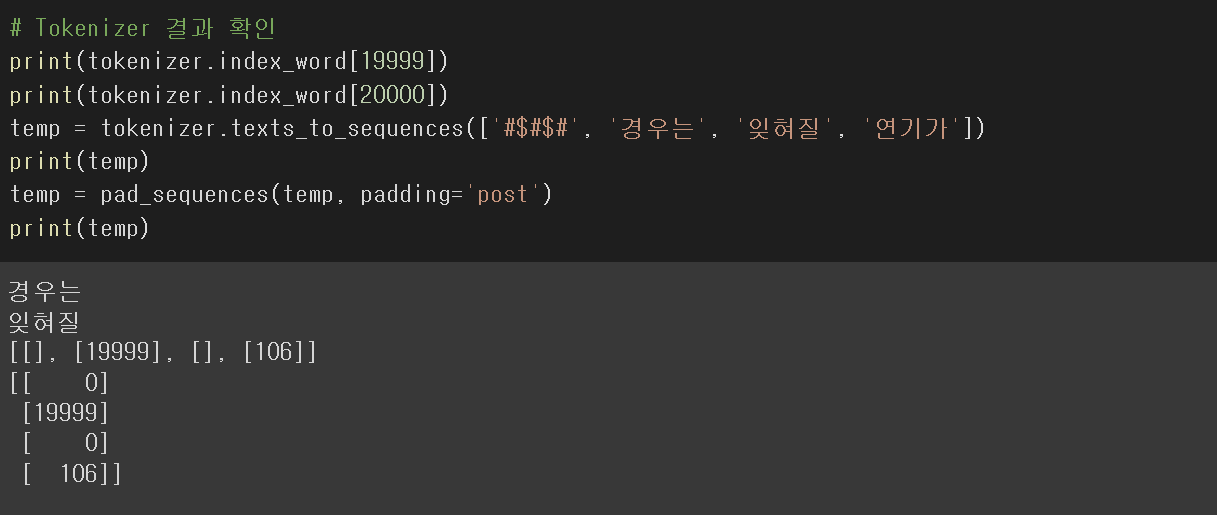
패딩 삽입과 Word Embedding
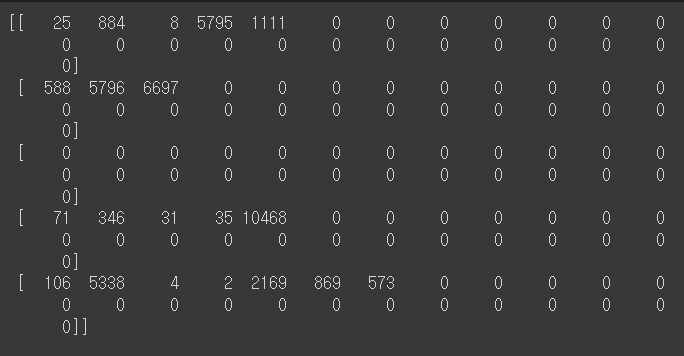
패딩을 넣어주어 단어 길이를 일정하게 맞추어 준다.
하나 하나의 문장들의 패딩을 맞추어 가중치를 똑같이 해준다.
문장 길이 일정화
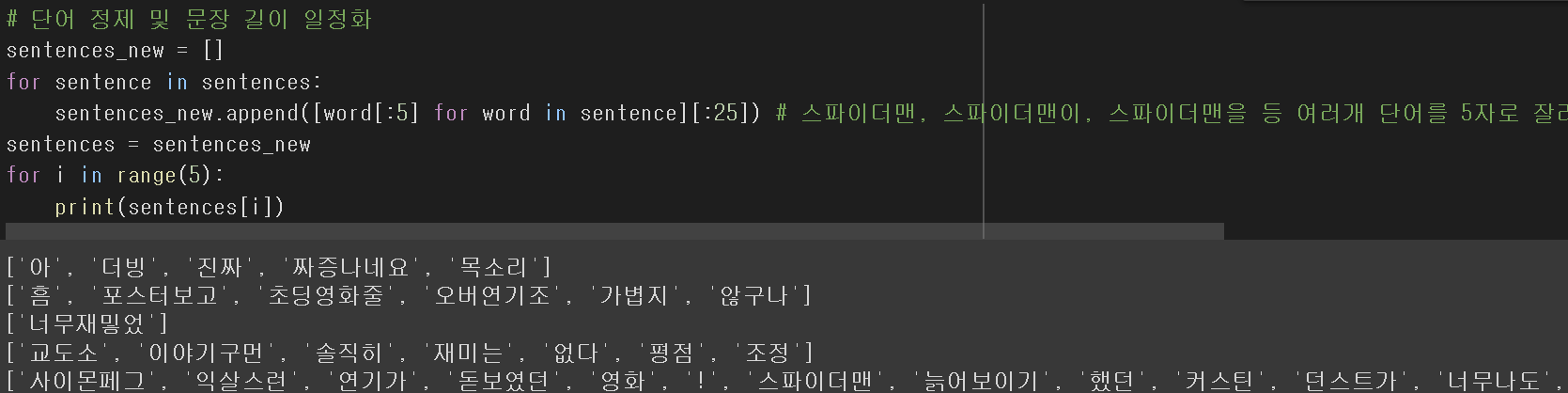
25개 단어 기준으로 문장을 잘라준다.
한 문장은 5개의 글자 수 기준으로 자른다.

모델 학습

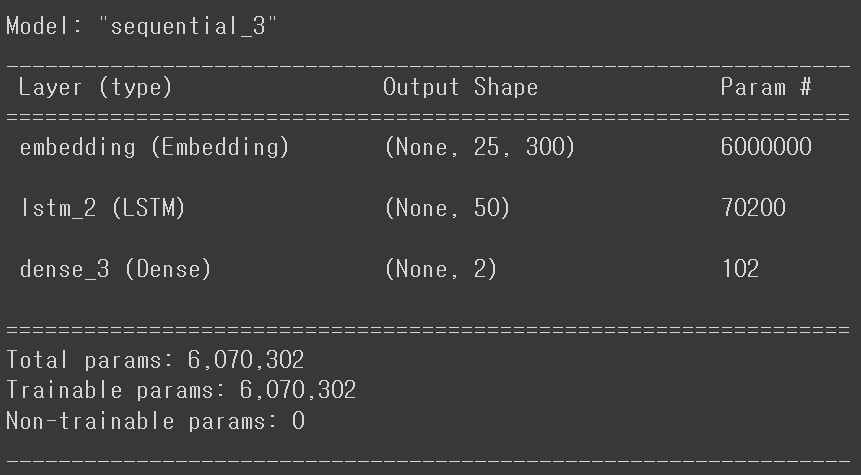
LSTM에 Embedding 값을 넣어준다.(20000개의 단어 수를 200차원으로 embedding한다. 문장 길이는 25개이다.)
모델 학습

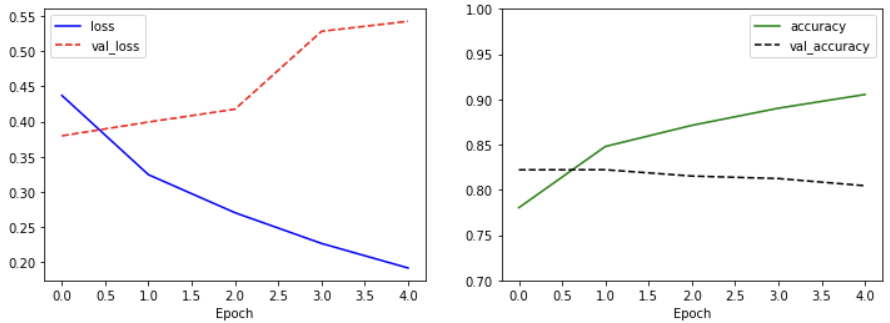
학습 평가
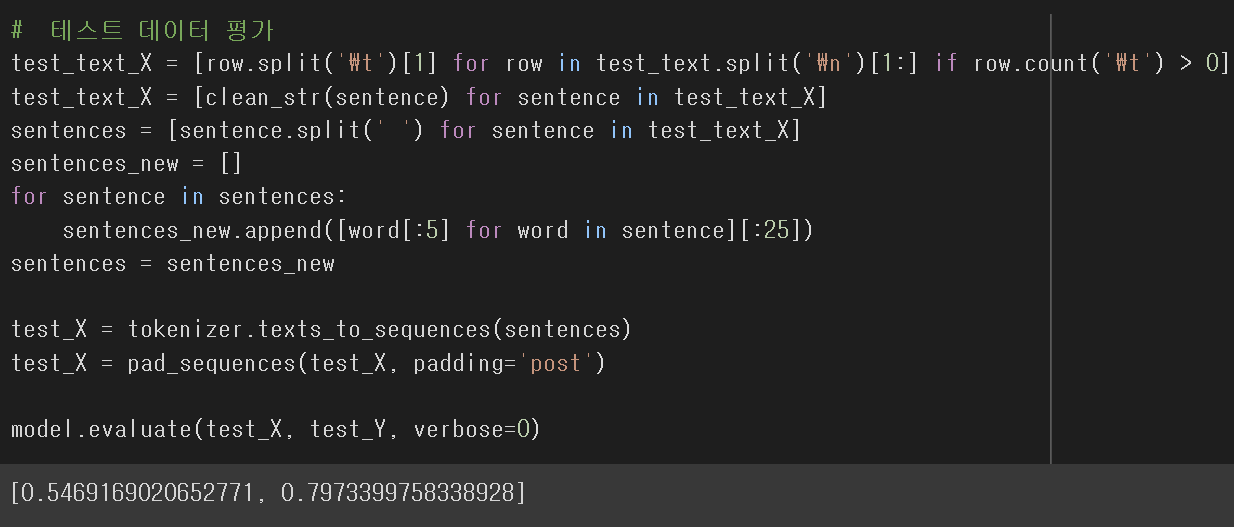
학습된 모델의 문장 분류에서 79.7%의 정확성을 보여주고 있다.

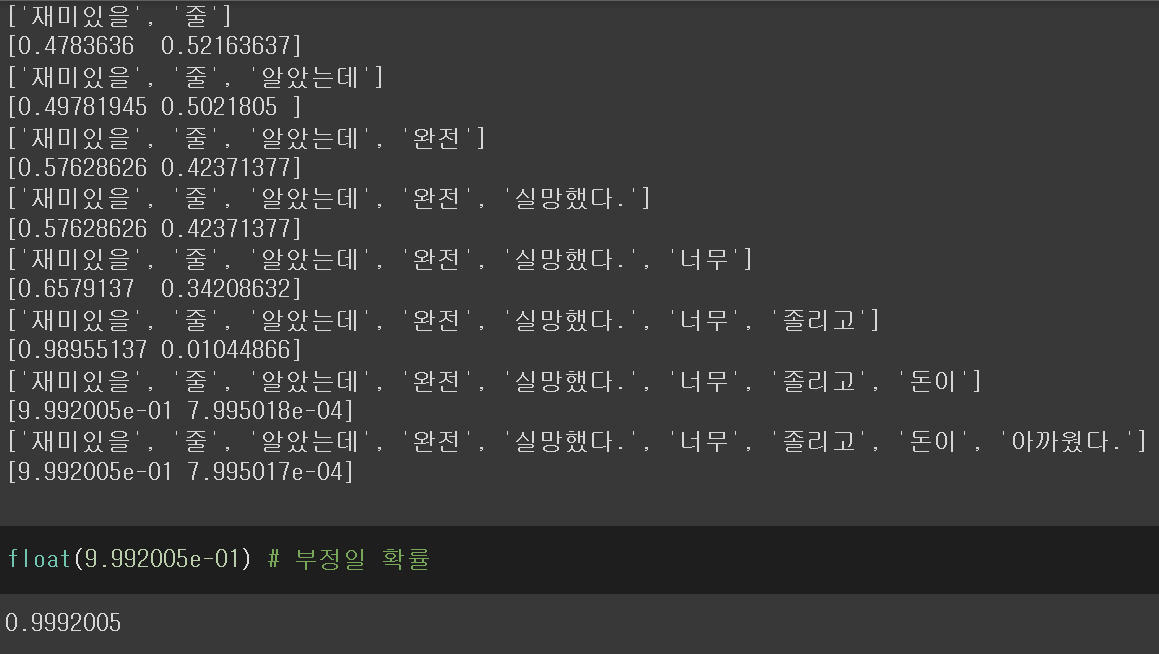
'재미있을 줄 알았는데 완전 실망했다. 너무 졸리고 돈이 아까웠다'라는 문장을 99.9%의 확률로 부정적인 문장으로 평가하였다.
'플레이데이터 빅데이터 부트캠프 12기 > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [플레이데이터 빅데이터 부트캠프]딥러닝 미니 프로젝트 (0) | 2022.08.13 |
|---|---|
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 텍스트 분석 기초 (0) | 2022.08.11 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 Teachable Machine (0) | 2022.08.10 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 전이 학습 (0) | 2022.08.10 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 CNN (0) | 2022.08.10 |