

크롤링
웹 크롤링은 기존의 복사본 만들기, 웹 스크래핑은 분석을 위한 특정 데이터를 추출하거나 새로운 것을 만들기를 의미합니다.
- crawling은 다 긁어오는 것, scraping은 필요한 부분을 잘라오는 것
- 웹 스크래핑을 수행하기 위해서는 먼저 필요한 정보를 찾는 웹 크롤링이 수행되어야 합니다
웹 사이트에서 내용을 가져오는 방법
- 텍스트, 영상, 음성, 그림
- 저작권 문제가 있고, 트래픽을 유발하므로 일반적으로 허용하지 않습니다.
오픈 API를 통해서 가져오는 방법
- 수집을 허용하기 때문에 회사나 공공기관에서 API가 제공된다.
API란?
응용 프로그램에서 사용할 수 있도록, 운영 체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스이다.
urllib을 통한 HTTP 통신
- 파이썬 기본 패키지
- 따로 설치가 필요없이 바로 사용이 가능
import urllib.request
url = 'http://info.cern.ch'
request = urllib.request.Request(url) # 요청
response = urllib.request.urlopen(request) # 응답
print(response.read().decode())위의 코드를 입력하면, url 상의 정보를 모두 크롤링해 올 수 있다.
import urllib.request
from fake_useragent import UserAgent
agent = UserAgent()
header = {'User-Agent' : agent.chrome }
url = 'https://upload.wikimedia.org/wikipedia/ko/thumb/4/4a/%EC%8B%A0%EC%A7%B1%EA%B5%AC.png/230px-%EC%8B%A0%EC%A7%B1%EA%B5%AC.png'
path = 'download.jpg'
# request = urllib.request.Request(url) # 요청
# response = urllib.request.urlopen(request) # 응답
urllib.request.urlretrieve(url, path) # 응답urlib을 통한 파일 저장 이미지 가져오기
!pip install fake_useragentimport urllib.request
from fake_useragent import UserAgent
agent = UserAgent()
header = {'User-Agent' : agent.chrome }
url = 'https://upload.wikimedia.org/wikipedia/ko/thumb/4/4a/%EC%8B%A0%EC%A7%B1%EA%B5%AC.png/230px-%EC%8B%A0%EC%A7%B1%EA%B5%AC.png'
path = 'download.jpg'
# request = urllib.request.Request(url) # 요청
# response = urllib.request.urlopen(request) # 응답
urllib.request.urlretrieve(url, path) # 응답request를 통한 파일 저장
import requests
url = 'http://info.cern.ch'
response = requests.get(url)
print(response.text)파일을 그대로 쓰는 방법
import requests
url = 'http://info.cern.ch'
response = requests.get(url)
with open('1.html', 'w') as f:
print(response.text, file=f)크롤링 해서 바로 다운받아서 볼 수 있다. 이미지도 다운받아서 볼 수 있다. (참고 네이버 베너)
BeautifulSoup
받아온 html을 파싱하기 위해 사용하는 패키지이다.
네이버 평점을 크롤링하고, 전처리 해보자.
import requests
url = 'https://movie.naver.com/movie/point/af/list.naver'
# requests 패키지를 통해 위 url을 크롤링해오세요!
html = response.textFind 메소드로 원하는 태그를 찾을 수 있다.
element = review.find('a')
type(element)
elements = review.findAll('a')id는 페이지당 하나만 가지고 있고, .은 클래스와 비슷한 역할을 하고 자료를 하나의 클래스로 관리한다.
elements = review.findAll('td', class_="title")att = {'class':'title'} # key=value
# 태그명을 검색할 수 있습니다
elements = review.find_all('td', attrs=att)
elements, type(elements)네이버 영화 페이지에서 영화제목과 평점 등을 가져와 보자.
elements[0].text
elements[0].text.split('\n')[1] # 영화제목
elements[1].text.split('\n')[3] # 별점
elements[1].text.split('\n')[5] # 리뷰elements 객체 안에서 리뷰와 별점 그리고 제목을 각각 모은 리스트를 출력해 보세요.
import bs4
import requests
url = 'https://movie.naver.com/movie/point/af/list.naver'
response = requests.get(url)
html = response.text
review = bs4.BeautifulSoup(html)
# 리뷰만 확인
att = {'class':'title'}
elements = review.find_all('td', attrs=att)
for element in elements:
subject = element.text.split('\n')[1]
star = element.find('em').text
review = element.text.split('\n')[5]
print(f'영화제목: {subject}, 별점: {star}, 리뷰: {review}')elements 안에서 em 태그가 별점을 감싸고 있는 것을 사용하여, find 메소드를 사용하여 별점을 뽑아내었다.
나머지 리뷰들도 가져오려면?
페이지 번호를 입력하면 자동으로 데이터프레임을 만들어주는 함수도 만들어줄 수 있다.
# movie_review(페이지넘버) 실행하면 movieDf(데이터프레임)를 만들어주는 함수 만들어주세요 1~n페이지까지 출력
def movie_review(page_num):
reviewList, stars, subjects = [],[],[]
for num in range(1, page_num+1):
url = f'https://movie.naver.com/movie/point/af/list.naver?&page={num}'
response = requests.get(url)
html = response.text
review = bs4.BeautifulSoup(html)
elements = review.find_all('td', attrs={'class':'title'})
for e in elements:
subjects.append(e.text.split('\n')[1])
stars.append(e.text.split('\n')[3].split('중')[-1])
review = e.text.split('\n')[5]
if review == '':
reviewList.append('No review')
else:
reviewList.append(e.text.split('\n')[5])
return pd.DataFrame({'title':subjects, 'score':stars, 'review':reviewList})
movieDf = movie_review(3)
movieDf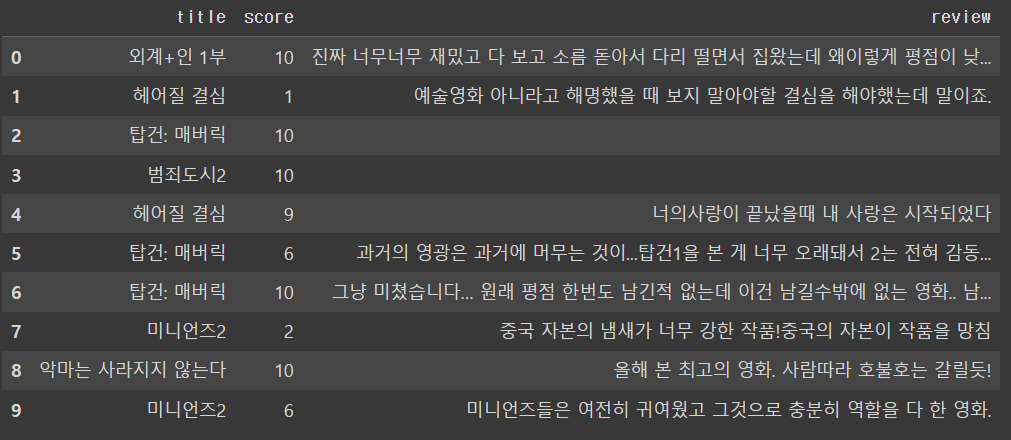
Selenium
실제로 브라우저를 제어하여, 데이터를 수집, 자동화 등을 하기 위한 패키지이다.
!pip install seleniumfrom selenium import webdriver
# 크롬드라이버 경로 지정
driver = webdriver.Chrome('./chromedriver.exe')
# get - 가고 싶은 주소로 이동
driver.get('https://naver.com')
# 종료 - 안해주면 계속 창이 열려있어요!!
# driver.quit()webdrriver manager 설치
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service # 크롬드라이버의 동작 시작, 끝 담당
from selenium.webdriver.common.by import By # CSS선택자 서치 담당
from selenium.webdriver.common.keys import Keys # 키 관련 동작 담당
# 크롬드라이버 경로 지정
chrome_driver = ChromeDriverManager().install()
service = Service(chrome_driver)
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging']) # USB에 부착된~ 버그 로그 제거용
# webdriver
# 크롬을 기준으로 현재 사용하고 있는 버전에 맞춰서 webdriver를 다운로드
browser = webdriver.Chrome(service=service, options=options)
url = 'https://www.naver.com'
browser.get( url )
# 검색어 입력 후 엔터 입력
element = browser.find_element(By.CSS_SELECTOR, 'input#query')
element.send_keys('검색어')
element.send_keys('\n')
# 검색어 입력 후 마우스 클릭
# 클릭 가능한 요소라면 클릭이 가능
input = browser.find_element(By.CSS_SELECTOR, 'input#query')
button = browser.find_element(By.CSS_SELECTOR, 'button#search_btn')
input.send_keys('검색어')
button.click()
input2 = browser.find_element(By.CSS_SELECTOR, 'input#nx_query')
input2.clear()
input2.send_keys('두번째 검색어')
input2.send_keys('\n')
# browser.quit()selenium은 element 메소드로 원하는 값을 추출한다.
사용법
요소.send_keys("텍스트")
- 해당 요소에 문자 입력하기
- .send_keys(Keys.CONTROL, 'v')
요소.click()
- 해당 요소 클릭하기
driver.execute_script("JS 스크립트")
- 화면상 스크롤 위치 이동 : scrollTo(x,Y) ,scrollTo(x,Y+number)
- 화면 최하단으로 스크롤 이동 : scrollTo(0, document.body.scrollHeight)
- 화면을 움직이고 페이지 로드 기다리기 : time.sleep(second)
페이지가 달라질 때마다, 우리가 찾고 있는 박스가 맞는지 확인해준다.
중고나라 크롤링 코드
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging']) # USB에 부착된~ 버그 로그 제거용
options.add_experimental_option("detach", True) # 자동종료 막기
chrome_driver = ChromeDriverManager().install()
service = Service(chrome_driver)
driver = webdriver.Chrome(service=service, options=options)
# 이후 원하는 동작 제시
# 네이버 로그인 페이지 접속
login_url = "https://nid.naver.com/nidlogin.login"
driver.get(login_url)
time.sleep(2)
# # # 아이디, 비밀번호 변수에 저장
my_id = "내 아이디"
my_pw = "내 비밀번호"
# # # 아이디, 비밀번호 입력
driver.execute_script("document.getElementsByName('id')[0].value = '" + my_id + "'") # driver.execute_script() 안에 자바스크립트 사용 가능
driver.execute_script("document.getElementsByName('pw')[0].value = '" + my_pw + "'")
# 중고나라 접속
cafe_joong = "https://cafe.naver.com/joonggonara"
driver.get(cafe_joong)
time.sleep(1)
# '조던 판매 게시판' 클릭
menu = driver.find_element(By.ID, "menuLink2171")
menu.click()
time.sleep(1)
# 프레임 확인: 개발자 도구 → iframe 검색
driver.switch_to.frame("cafe_main")
time.sleep(1)
# # XPath란? 웹 페이지의 구조 최상단부터 태그를 타고 들어가, 해당 HTML 요소가 어디에 존재 하는 지를 나타내는 경로의 일종
xpath = "/html/body/div[1]/div/div[4]/table/tbody/tr[1]/td[1]/div[2]/div/a"
# # 첫번째 글 클릭
writing = driver.find_element(By.XPATH, xpath)
writing.click()
time.sleep(1)
# 첫번째 글 제목 출력
subject = driver.find_element(By.CSS_SELECTOR, "h3.title_text").text # 제목만
# # 첫번째 글 내용 출력
content = driver.find_element(By.CSS_SELECTOR, "div.se-main-container").text # 내용만 출력
print(subject, content)
time.sleep(100)
driver.close()
'플레이데이터 빅데이터 부트캠프 12기 > Python' 카테고리의 다른 글
| [플레이데이터 빅데이터 부트캠프]Python Open API 만들기(2) (0) | 2022.07.27 |
|---|---|
| [플레이데이터 빅데이터 부트캠프]Python Open API 만들기(1) (0) | 2022.07.26 |
| [플레이데이터 빅데이터 부트캠프]Python 데이터 시각화 PLOTLY(2) (0) | 2022.07.25 |
| [플레이데이터 빅데이터 부트캠프]Python 데이터 시각화 PLOTLY(1) (0) | 2022.07.25 |
| [플레이데이터 빅데이터 부트캠프]Python 데이터 시각화(2) (0) | 2022.07.22 |