

이중 분류
사이킷런에는 0~9까지의 손글씨 이미지를 제공하는 load_digits 데이터 셋이 있다. 해당 데이터셋을 받아와서 데이터를 전처리하고, Decision Tree 분류기로 0과 0이 아닌 이미지로 이중 분류하고, 성능을 평가해보자.






다중 분류
이제 10개 숫자 중 0만을 판별하는 조건을 없애고, 0~9까지 모두 분류하는 모델을 만들고 평가하여 보자.

분류의 갯수를 높이니 정확도가 살짝 낮아진 것을 확인할 수 있다.
모델평가
- 만약 모델을 검증했을 경우 정확도가 확 떨어질 경우 과적합화 된 경우라고 판단할 수 있다.
- 테스트 셋은 100만 개 정도 있으면 10% 정도 쓰면 된다.
- 과소평가란? 진짜 중요한 피쳐들을 떨어뜨려, 데이터를 학습하기에 정확성이 떨어지는 것을 말한다.
- 교차 검증을 통해 과대평가 과소평가를 막을 수 있다.
KNN
K Nearest Neighbors(K-최근접 이웃 분류 알고리즘)
- 가장 고전적이고 직관적인 머신러닝 분류 알고리즘
- 기하학적 거리 분류기
- 가장 가깝게 위치하는 멤버로 분류하는 방식
- hyperparameter인 K값은 근처에 참고(reference)할 이웃의 숫자
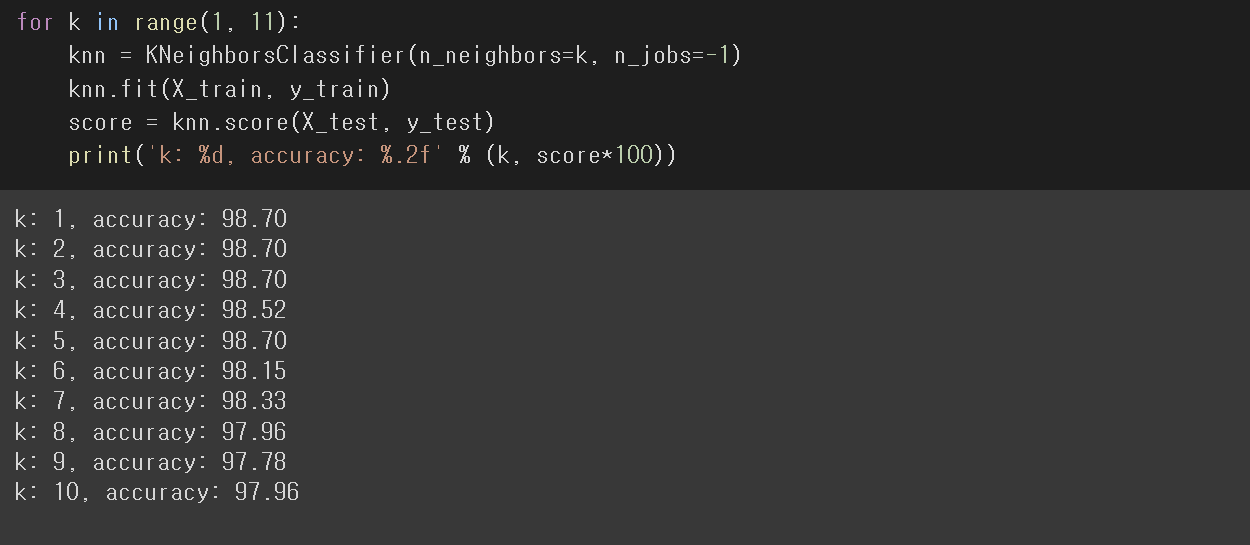
KNN을 사용한 0~9 손글씨 분류기 만들기


Test_size는 0.3으로 설정하였다.

n_jobs는 학습에 사용할 코어의 숫자를 지정합니다. -1로 지정하면 모든 코어를 사용합니다.


최적의 n-neighbors 찾기
GridSesearCV를 사용하여 iris data를 사용하였을 경우, 최적의 파라미터 찾기

GridSearchCV를 사용하기 전에 gs 메소드 확인하여 보자.

우리는 여기서, gs.best_estimator_, gs.best_score_, gs.best_params_를 사용해 볼 것이다.

데이터전처리
Scaling
- 스케일 방법으로 표준화(Standardization)와 정규화(Normalization) 방법이 있다.
- 데이터를 사용자가 볼 수 있는 범위안에 넣어주는 과정이다.
- 사이킷런의 프리프로세싱 모듈에 있다.
StandardScaler:표준화 클래스
- 가우시안 분포를 가정한, 선형 회귀, 로지스틱 회귀 모델에 많이 쓰인다.
- 표준화하고 해야지 모델에 도움이 된다.
- 차원을 공통 크기로 만들어준다.
- 피쳐들 사이의 차원을 없애주어 나타낸다. (0~1 사이로 일정하게 맞혀준다.)

fit은 데이터에 알맞는 스케일 조건을 학습하고, transform은 데이터에 적용할 때 사용한다.
fit과 trnasform을 동시에 사용할 때, fit_transform()을 사용한다. 연산 속도 향상에 도움이 된다.
MinMaScaler:정규화 클래스
- 정규분포가 아닐 때 사용한다.
- -1~1 사이의 값으로 만들어준다.

feature scailing 시 주의사항
- 학습 데이터와 데이터 데이터에 각각 fit() 적용하면 안 된다.
- 만약 테스트 데이터에 새로 fit()을 하게 되면 학습 데이터와 테스트 데이터의 스케일링 기준 정보가 달라지는 문제가 생긴다.
- 가장 좋은 방법은 학습용 데이터와 테스트용 데이터를 분리하기 전에 피쳐 스케일링을 적용하는 방법이다.
Encoding
Label Encoder
- 머신러닝 알고리즘은 문자열 데이터를 입력으로 받지 못한다.
- 따라서, 데이터가 가지고 있는 범주형 데이터는 반드시 숫자형으로 변환해주어야 한다.
- 문자열들을 숫자로 매기는 인코딩이다.
seaborn의 Tips 데이터를 바탕으로 label encoding을 연습하여 보자.

from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
# # 방법1
# encoder = encoder.fit(tips['day'])
# encoded = encoder.transform(tips['day'])
#방법2
encoded = encoder.fit_transform(tips['day'])sklearn LabelEncoder를 사용하면, 문자열을 ndarray로 형태를 바꿔준다.

Inverse Transform(역변환)
결과 확인을 위하여 숫자형으로 변환한 범주형(Categorical) 데이터를 원래대로 되돌려 준다.
LabelEncoder의 inverse_transform 메소드를 사용하여 역변환 해본다.
inversed = encoder.inverse_transform(encoded)
inversed
array(['Sun', 'Sun', 'Sun', 'Sun', 'Sun', 'Sun', 'Sun', 'Sun', 'Sun',
'Sun', 'Sun', 'Sun', 'Sun', 'Sun', 'Sun', 'Sun', 'Sun', 'Sun',
'Sun', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat',
'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat',
.....
'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat',
'Sat', 'Fri', 'Fri', 'Fri', 'Fri', 'Fri', 'Fri', 'Fri', 'Sat',
'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat',
'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Sat', 'Thur'], dtype=object)One Hot Encoder
보통 label encoding을 먼저 하고 One Hot Encoding을 한다.
회귀문제에서는 의미를 해석해야 되므로, One Hot Encoding을 주로 사용한다.
예시문제로 items = ['사과', '바나나', '딸기', '오렌지', '포도']를 One Hot Encoding 해본다.
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelEncoder
items = ['사과', '바나나', '딸기', '오렌지', '포도']
# 라벨인코딩을 해 주세요
# 각각 어느 숫자와 어느 단어가 매칭이 되었는지 확인해주세요
label_encoder = LabelEncoder()
encoder = label_encoder.fit_transform(items)
# 원핫인코더 객체 생성
one_encoder = OneHotEncoder()
# 2차원 구조로 변환해주는 작업이 필요합니다.
labels = encoder.reshape(-1, 1)
# 원핫인코더로 변환
onehot = one_encoder.fit_transform(labels)여기서, 원핫인코더에 대입하려면 배열을 2차원 구조로 만들어 줘야 한다.->reshape(-1, 1)
reshape 메소드는 배열의 차원을 변경할 때 사용하는 메소드이다.
(아래는 reshape 메소드의 예시 코드이다.)
import numpy as np
x=np.arange(12)
print('x= {}'.format(x))
x= [ 0 1 2 3 4 5 6 7 8 9 10 11]
x.reshape(-1, 1)
array([[ 0],
[ 1],
[ 2],
[ 3],
[ 4],
[ 5],
[ 6],
[ 7],
[ 8],
[ 9],
[10],
[11]])
x.reshape(-1, 2)
array([[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7],
[ 8, 9],
[10, 11]])이제 2차원 배열로 만든 인코더를 원핫인코더 객체에 대입해 본다.
onehot = one_encoder.fit_transform(labels)
onehot
print(onehot)
type(onehot) # 압축된 csr_matrix라는 형식으로 가지고 있다가 필요할 때 펼쳐서 꺼내씁니다(제너러이터랑 비슷)
onehot.toarray() #->압축된 자료형을 다시 ndarray로 만들어준다.결과를 확인하여 보자. 결과물은 압축된 matrix 형식으로 보여준다.

압축된 matrix를 아래처럼 ndarray 형식으로 확인하려면, toarray()라는 메소드를 사용해야 된다. 아래와 같이 toarray() 메소드를 사용하여, OneHotEncoding이 완료된 것을 확인할 수 있다.

'플레이데이터 빅데이터 부트캠프 12기 > 머신러닝 & 딥러닝' 카테고리의 다른 글
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 Ensemble (0) | 2022.08.05 |
|---|---|
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 회귀(Regression)(2) (0) | 2022.08.05 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 회귀(Regression)(1) (0) | 2022.08.04 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 타이타닉 데이터(캐글 튜토리얼) (0) | 2022.08.04 |
| [플레이데이터 빅데이터 부트캠프]머신러닝 & 딥러닝 머신 러닝 기초(1) (0) | 2022.08.01 |